- Kloudnative
- Posts
- Interview: In Case Redis Crashes, How to Avoid Data Loss (AOF Log)?
Interview: In Case Redis Crashes, How to Avoid Data Loss (AOF Log)?
Strategies for Preventing Data Loss
Vivek Sonar
October 30, 2024
If someone asks you, “In what business scenarios would you use Redis?” I think you will most likely say, “I will use it as a cache because it stores the data in the back-end database in memory and then reads data directly from memory, so the response speed will be very fast.” Yes, this is indeed a common usage scenario of Redis.
However, there is also an issue that absolutely cannot be ignored: Once the server crashes, all the data in memory will be lost. 😱
An obvious solution that comes to mind is to restore these data from the back-end database. However, this approach has two problems:
First, frequent access to the database will bring huge pressure to the database.
Second, these data are read from a slow database. The performance is definitely not as good as reading from Redis, resulting in slower response of applications using these data.
Therefore, for Redis, implementing data persistence and avoiding recovery from the back-end database is crucial.
Persistence methods
Redis provides mainly two data persistence methods:
AOF (Redis Database Backup file): A log file that appends commands in real time.
RDB (Append Only File): Generates a data snapshot file.
In this article, let’s focus on learning the implementation of AOF first.
How is the AOF log implemented?
When it comes to logs, we are more familiar with the write-ahead log (WAL) of databases. That is, before actually writing data, the modified data is first recorded in the log file for recovery in case of failure.
However, the AOF log is just the opposite. It is a write-after log. That is, Redis first executes the command, writes the data into memory, and then records the log, as shown in the following figure:

In addition, in Redis, the AOF persistence function is not enabled by default. We need to modify the following parameters in the redis.conf configuration file:
// redis.conf
appendonly yes //Indicates whether to enable AOF. The default is no.
appendfilename "appendonly.aof" //The name of the AOF file.Redis AOF operation process
So why does AOF record the log after executing the command first? To answer this question, we need to know what is recorded in the AOF first.
The logs of traditional databases, such as MySQL’s redo log, record the modified data. While the AOF records every command received by Redis, and these commands are saved in text form.
Let’s take the log recorded after Redis receives the command set testkey testvalue as an example to see the content of the AOF log.
Among them, *3 indicates that the current command has three parts, and each part starts with $+digital, followed by the specific command, key or value. Here, "digital" indicates how many bytes there are in the command, key or value in this part. For example, $3 set means there are 3 bytes in this part, which is the set command. $7 testkey means the string length of the key.
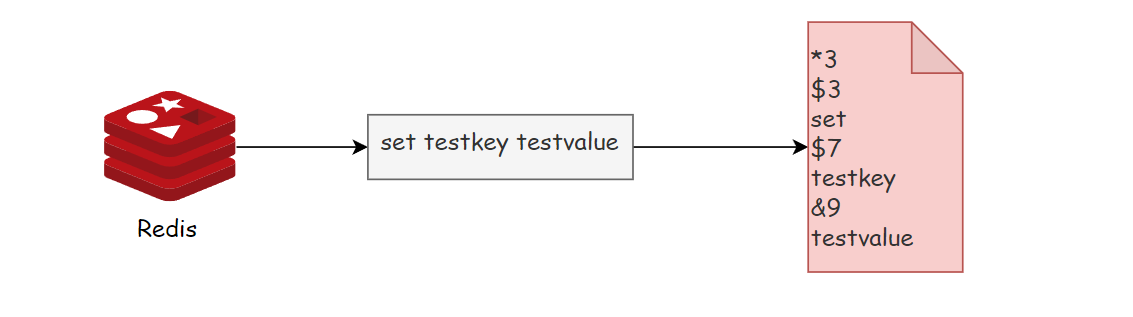
Redis AOF log content
However, to avoid additional checking overhead, when Redis records logs in the AOF, it will not perform syntax checking on these commands first. So, if the log is recorded first and then the command is executed, there may be incorrect commands recorded in the log, and when Redis uses the log to restore data, errors may occur.
The write-after logging method is to let the system execute the command first. Only if the command can be executed successfully will it be recorded in the log. Otherwise, the system will directly report an error to the client. Therefore, a major advantage of Redis using the write-after logging method is that it can avoid recording incorrect commands.
In addition, AOF has another advantage: it records the log after the command is executed, so it will not block the current write operation.
However, AOF also has two potential risks.
First, if a command has just been executed and the system crashes before the log can be recorded, then there is a risk of losing this command and the corresponding data. If Redis is used as a cache at this time, data can be read back from the back-end database for recovery. However, if Redis is directly used as a database, at this time, because the command is not recorded in the log, it cannot be recovered using the log.
Second, although AOF avoids blocking the current command, it may bring blocking risks to the next operation. This is because the AOF log is also executed in the main thread. If there is high disk write pressure when writing the log file to the disk, it will lead to slow disk writing, and then subsequent operations cannot be executed.
Upon careful analysis, you will find that these two risks are both related to the timing of writing the AOF log back to the disk. This means that if we can control the timing of writing the AOF log back to the disk after a write command is executed, these two risks will be eliminated.
Three write-back strategies
In fact, for this problem, the AOF mechanism provides us with three choices, which are the three optional values of the AOF configuration item appendfsync.
Always, synchronous write-back: After each write command is executed, the log is immediately synchronously written back to the disk.
Everysec, write back every second: After each write command is executed, only the log is first written to the memory buffer of the AOF file, and the content in the buffer is written to the disk every second.
No, write-back controlled by the operating system: After each write command is executed, only the log is first written to the memory buffer of the AOF file, and the operating system decides when to write the buffer content back to the disk.
For avoiding blocking the main thread and reducing data loss, none of these three write-back strategies can achieve both. Let’s analyze the reasons.
“Synchronous write-back” can basically avoid data loss, but it has a slow disk write operation after each write command, which inevitably affects the performance of the main thread.
Although “write-back controlled by the operating system” can continue to execute subsequent commands after writing the buffer, the timing of disk writing is no longer in the hands of Redis. As long as the AOF record is not written back to the disk, once the system crashes, the corresponding data will be lost.
“Write back every second” uses a frequency of writing back once a second, avoiding the performance overhead of “synchronous write-back”. Although it reduces the impact on system performance, if a crash occurs, the command operations that have not been written to the disk in the previous second will still be lost. So, this can only be regarded as a compromise between avoiding affecting the performance of the main thread and avoiding data loss.
I have summarized the write-back timings, advantages and disadvantages of these three strategies in a table for your convenience to view at any time.

At this point, we can choose which write-back strategy to use according to the system’s requirements for high performance and high reliability. In summary:
If you want high performance, choose the No strategy.
If you want high reliability guarantees, choose the Always strategy.
If you allow a little data loss and hope that the performance will not be greatly affected, then choose the Everysec strategy.
However, after selecting the write-back strategy according to the system’s performance requirements, it is not “completely worry-free”. After all, AOF records all received write commands in the form of a file. As more and more write commands are received, the AOF file will become larger and larger. This means that we must be careful about the performance issues caused by an overly large AOF file.
The “performance issues” here mainly lie in the following three aspects:
First, the file system itself has limitations on file size and cannot save overly large files.
Second, if the file is too large, the efficiency of appending command records to it later will also become lower.
Third, if a crash occurs, the commands recorded in AOF need to be re-executed one by one for fault recovery. If the log file is too large, the entire recovery process will be very slow, which will affect the normal use of Redis.
So, we need to take certain control measures. At this time, the AOF rewrite mechanism comes into play.
AOF rewrite mechanism
Simply put, the AOF rewrite mechanism is that Redis creates a new AOF file according to the current status of the database. That is, read all key-value pairs in the database, and then use one command to record its write for each key-value pair.
For example, after reading the key-value pair “testkey”: “testvalue”, the rewrite mechanism will record the command set testkey testvalue. In this way, when recovery is needed, this command can be re-executed to achieve the writing of “testkey”: “testvalue”.
Why can the rewrite mechanism reduce the size of the log file? In fact, the rewrite mechanism has a merging function. That is, multiple commands in the old log file become one command in the rewritten new log file.
We know that the AOF file records the received write commands one by one in an append-only manner. When a key-value pair is repeatedly modified by multiple write commands, the AOF file will record the corresponding multiple commands.
However, during rewriting, according to the current latest state of this key-value pair, a corresponding write command is generated for it. In this way, a key-value pair only needs one command in the rewritten log. Moreover, during log recovery, only by executing this command can the writing of this key-value pair be directly completed.
The following figure is an example:

After we have performed six modification operations on a list successively, the final state of the list is [“F”, “E”, “D”]. At this time, only the command Lpush mylist D E F can be used to achieve the restoration of this data, which saves the space of five commands. For key-value pairs that have been modified hundreds or thousands of times, the space saved by rewriting is of course even greater.
However, although the log file will be reduced after AOF rewriting, it is still a very time-consuming process to write back the operation logs of the latest data of the entire database to the disk. At this time, we have to continue to pay attention to another problem: Will rewriting block the main thread?
Will AOF rewriting block?
Unlike AOF logging being recorded by the main thread, the rewriting process is completed by the background child process bgrewriteaof, which is also to avoid blocking the main thread and causing a decrease in database performance.
I summarize the rewriting process as “one copy, two logs”.
“One copy” means that every time rewriting is executed, the main thread forks the background bgrewriteaof child process. At this time, fork will copy the memory of the main thread to the bgrewriteaof child process, which contains the latest data of the database. Then, the bgrewriteaof child process can, without affecting the main thread, write the copied data into operations one by one and record them in the rewrite log.
What are “two logs”?
Since the main thread is not blocked and can still handle new operations. At this time, if there is a write operation, the first log refers to the currently used AOF log. Redis will write this operation to its buffer. In this way, even if the system crashes, the operations in this AOF log are still complete and can be used for recovery.
The second log refers to the new AOF rewrite log. This operation will also be written to the buffer of the rewrite log. In this way, the rewrite log will not lose the latest operations. After all the operation records of copying data are rewritten, these latest operations recorded in the rewrite log will also be written to the new AOF file to ensure the recording of the latest state of the database. At this time, we can replace the old file with the new AOF file.
In summary, every time AOF is rewritten, Redis will first perform a memory copy for rewriting. Then, two logs are used to ensure that newly written data will not be lost during the rewriting process. Moreover, because Redis uses an additional thread for data rewriting, this process will not block the main thread.
Summary
You may have noticed that both the disk-writing timing and the rewrite mechanism play a role in the process of “logging”. For example, the selection of disk-writing timing can avoid blocking the main thread when logging, and rewriting can avoid excessive log file size. However, in the process of “using the log”, that is, when using AOF for fault recovery, we still need to run all the operation records again. Coupled with Redis’s single-threaded design, these command operations can only be executed one by one in sequence, and this “replay” process will be very slow.
So, is there a method that can both avoid data loss and recover faster? Of course there is, and that is the RDB snapshot. I will introduce it in the next article.